在 Dremel 论文中,Google 介绍了将嵌套 Schema 的数据使用列式方式存储的方法,提供了一个高效的列式存储格式模板。 我觉得论文中的介绍方式并不太直接,因此本文尝试重新阐述一下这个方法, 希望有一个更清晰的解释。
我们将论文 Figure 2 右上角的数据 Schema 复制过来,如下:
message Document {
required int64 DocId;
optional group Links {
repeated int64 Backward;
repeated int64 Forward;
}
repeated group Name {
repeated group Language {
required string Code;
optional string Country;
}
optional string Url;
}
}这是一个 Protocol Buffer 描述的数据结构,名字叫做 Document。 Document 的 Schema 中包含 required, optional 和 repeated 三种属性的字段, 一些字段由 group 关键字组合起来,并且 group 是可以嵌套的。
Google 在论文中解决的第一个问题,就是将上述自然但复杂嵌套的数据结构拆分, 以列式的方式存储每一个字段,以减少数据查询中的读写量, 使得海量数据中的快速分析成为可能。 而实现列式存储的 overhead 仅仅是两个非常简单的数字: Repetition Levels 和 Definition Levels。
为了理解这个方法,首先我们来看上述数据的 Protocol 定义。 上述定义将数据中的不同字段按照逻辑层级组织到不同的 group 里, 如果将 group 解释为字段定义的 Path,则 Document 共包含下面六个字段:
1DocId
2Links.Backward
3Links.Forward
4Name.Language.Code
5Name.Language.Country
6Name.Url因此,只需要为上面六个字段创建六个列,将字段中的值依次存储下来即可保存所有数据。 对于 Figure 2 中的两个数据样例 r1 和 r2,对应的六个列如 Figure 3 所示。

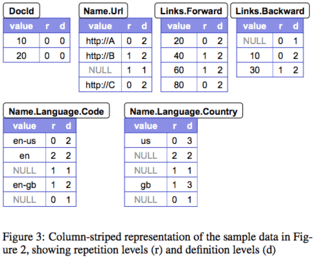
如果只有 Figure 3 中的 value 列,那么这个存储方式将丢失数据原有的结构信息。 例如,Links.Forward 列中的四个值,如无其他信息,是无从知道哪些是属于 DocId 10, 哪些是属于 DocId 20 的;又如 Name.Language.Code 的三个值,既可能是不同 Name 层的重复,又可能是同一 Name 的不同 Language,还可能是一个新的数据记录。 因此,Google 为每一列的每个值增加了 Repetition Levels 和 Definition Levels 两列附属信息。
Repetition Levels 表明了一个数据是在哪一个可 repeated 的层级上重复出现的。 例如 Name.Language.Code,Name 和 Language 都是 repeated 的,而 Code 是 required 的,那么 Code 的 Repetition Levels 可能有三个:
- Code 是一个新的记录中第一个值,则 Repetition Level 是 0;如 'en-us' 和第五行的 NULL (r2 中的唯一 Name 没有 Language 的定义,未定义的 Code 需要一个 NULL 占位);
- Code 不是记录中的第一个值,但是是一个新的 Name 中的第一个值,则 Repetition Level 是 1 (意思是在第一个可 repeat 的层级 Name 上重复的 Code);如 'en-gb' 和第三行的 NULL (r1 的第二个 Name 中没有 Language,因而 Code 为 NULL);
- Code 是一个新的 Language 中的值,而不是所在 Name 层的第一个值, 则 Repetition Level 是 2;如 'en';
同样的,可以知道 Name.Url 这个字段的 Repetition Level 只能取值 0 或 1, 分别代表新的记录中第一个值,或者 Name 字段的重复出现; Links.Forward 和 Links.Backward 字段亦然。
有了 Repetition Levels,就可以从列式存储中还原原有数据的定义了。 例如,考虑 Figure 3 中的列 Name.Language.Country, 让我们尝试自上而下读取这一列的 value 和 Repetition Levels, 并结合数据 Schema,尝试还原数据的原定义。
- 注意到数据定义中,Name 和 Language 都是 repeated 的,Country 是 optional 的;
- 第一个 value 是 'us',Repetition Level 0 意味着是一条新的数据记录;
- 第二个 value 是 NULL,Repetition Level 2 表明 NULL 仍在这条数据记录中, 并且仍是第一个 Name,而在 Language 字段上 Repeat, 因此这个 NULL 属于第一个 Name 的第二个 Language;
- 第三个 value 仍是 NULL,Repetition Level 则是 1,首先表明还是第一条数据记录, 然后这个 NULL 是 Name 这一层的重复,因此属于第二个 Name;
- 第四个 value 是 'gb',Repetition Level 是 1,同上,'gb' 属于第三个 Name;
- 第五个 value 是 NULL,Repetition Level 0 意味着是一条新的数据记录;
上述过程基本还原了 Name.Language.Country 这一列在原数据结构中的位置, 然而还有一个问题没有表达清楚。 我们看第 4 步的 NULL 这个值,Repetition Level 表明了它是第二个 Name 下的值, 然而第二个 Name 下 Country 为 NULL,既可能是从 Language 起就没有定义, 也可能是 Language 有定义,而 Country 没有定义。 同样,第五个 NULL 值也没能完全还原原定义层次。
可以看到,单独读取部分数据时,NULL 值仅有 Repetition Levels 不足以还原数据的原貌,这时,Definition Levels 就可以用来还原真相了。 观察 Figure 3 中各个 NULL value 的 Definition Levels 值,可以容易看到原数据定义: Name.Language.Country 列中第一个 NULL Definition Levels 是 2, 表明 Name 和 Language 有定义,而 NULL 值是 Country; 第二个 NULL 则表明只有 Name 有定义,Language 就为 NULL。
Definition Levels 仅在 repeated 字段和 optional 字段上有意义。因此, Name.Language.Country 的 Definition Levels 可能值为 3, 2, 1; 而 Name.Language.Code 的 Definition Levels 可能值为 2, 1, 因为 Code 是 required 字段。
通过 Definition Levels 的定义可以看到,所有有值的 value,其 Definition Level 都是其定义层次中 Definition Level 的最大值; 而所有小于这个最大值的 Definition Levels 数据,都表明 value 是 NULL。 因此 NULL 值在实际存储中是不必要存的,只要保存了 Definition Level 即可。
