Note on some commonly used distributed locks.
Use a relational database
We can use the locking mechanism provided by the database system for distributed applications: insert a record when locking, delete the record to unlock.
Note that the locking key should be unique index. There is no expire time by default, but we can let the application to check expiration.
Using this lock, we cannot block the process/thread when they failed to acquire the lock. Our application has to retry on failures, and the retry policy is important for performance.
The lock is also not reentrant. It means that the application cannot claim the lock multiple times without blocking on itself.
Use Redis
Single instance
We can have a single Redis instance and use SETNX with EXPIRE for locking.
The command SETNX tries to set a key-value pair if it does not exist.
For example:
SET resource_name unique_client_id NX PX 30000
In the above command,
NX means set if not exist,
PX 30000 means the expire time is set to 30000 milliseconds,
resource_name is the lock key,
and unique_client_id is the lock owner.
Note that we can use a Lua script to ensure that only the lock owner can release the lock.
The command returns True if it success,
and returns False if the key already exists.
Multiple instances
There is a Redlock algorithm that we can use to setup distributed with multiple Redis instances. And there are a bunch of libraries implement the algorithm.
Here is a brief summary of the algorithm:
- Consider a system with
NRedis masters - To acquire the lock, the client
- Get the current time in milliseconds
T1 - Sequentially try to acquire the lock in all the
Ninstances- Use a small timeout comparing to the lock expire time
- So that we do not wait too long on trying to talk to dead/slow nodes
- If an instance is not available, we should try to talk to the next instance ASAP
- Use a small timeout comparing to the lock expire time
- Consider the lock acquired if and only if
- The client was able to acquire the lock in the majority of the instances (
N/2+1) - The total time elapsed to acquire the lock is less than the lock validity time
- So that the client still has time to use the lock
- The client was able to acquire the lock in the majority of the instances (
- The lock validity time is the initial lock validity time (expire time) minus the time elapsed
- Get the current time in milliseconds
- If the client acquired the lock successfully
- Perform the task in the lock validity time
- Unlock all instances
- If the client failed to acquire the lock
- Unlock all instances ASAP
- Delay for a random time before retrying
Use Zookeeper
The Zookeeper namespace is a tree-like hierarchical namespace much like the standard file system.
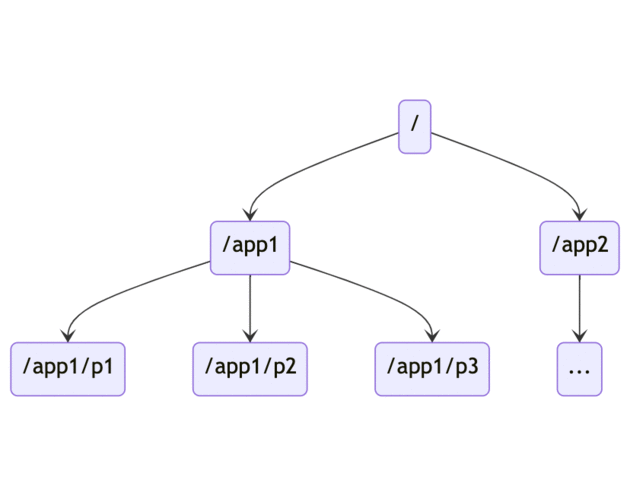
Each node in a Zookeeper namespace can have both data and children associated.
We use the term znode when talking about Zookeeper data nodes.
znodes are usually used to store small coordination data, such as status, configuration, location, etc.
And znodes also maintain a stat structure that includes the version number, ACL, timestamps, etc.
Zookeeper has the notion of ephemeral nodes which exists as long as the session that created the znode.
We can use the ephemeral flag when creating the node. When the session ends, the znode is deleted.
Zookeeper also supports sequence nodes.
New nodes will have a suffix X which is a monotonic increasing number.
We can use the sequence flag when creating the node to create sequence nodes.
For example, /lock/node-0000000000 and /lock/node-0000000001.
A client can set watches on znodes.
Changes to the znode trigger the watch and sends the client a notification.
Based on the above Zookeeper features, we can use the below lock implementation.
- Create a lock namespace
/lock - When a client tries to acquire the lock, it
- Create a node under
/lockwith theephemeralandsequenceflags - Get all children of
/lockwithout setting the watch flag- If the node created by me is the lowest sequence number
- Consider the lock acquired and exist the algorithm
- Watch the node with the next lowest sequence number
- Wait for a notification
- Create a node under
- To unlock, the client just need to delete the node it created
- On client failure, the node is ephemeral and will be deleted when the session ends
The client only watches on the next lowest sequence number instead of all nodes to avoid the herd effect.
Use Azure blob
Azure Storage support acquiring lease on blobs and we can use that as a distributed lock.
In a recent project I tested the performance of using a SQL server and Azure blob lease as a distributed lock. Azure blob's performance is good and we chose to use it in our project.
